

6·
4 days agoO_o I had no idea. This is really useful.
O_o I had no idea. This is really useful.
Another assumption that I wasn’t skeptical.
It wasn’t an assumption:
Anyway, you’ll see all this eventually, when some data gets published.
That is not a skeptical position.
And my point is that given that the data shows objectively that it does fool people - even subject matter experts - it is reasonable to believe that effect continues until proven otherwise. We know it’s a feature of LLMs, and the fact you continue to push on with your blind faith undisturbed by this knowledge is truly alarming.
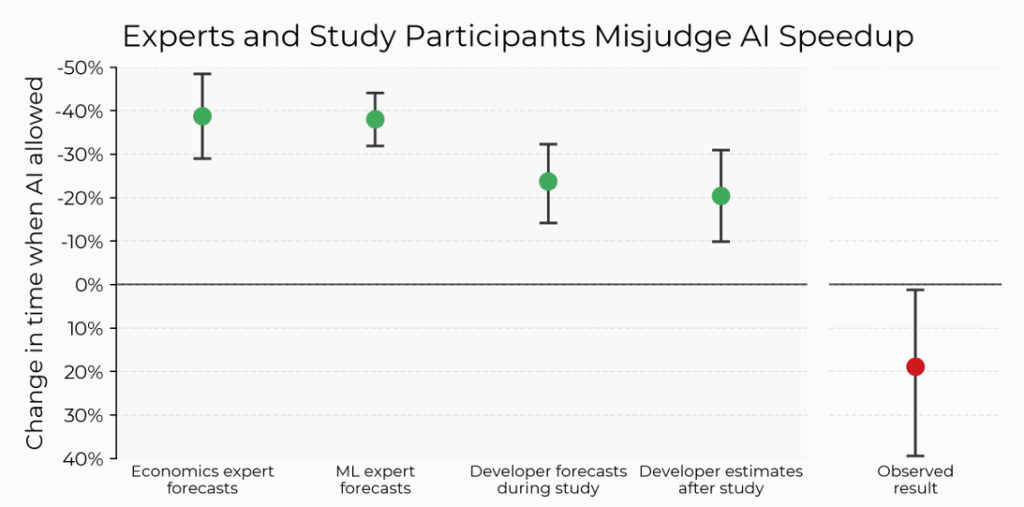
In the follow up study, first of all I want to point out that it’s not definitive that it made them faster, the error bars include regions where they were slowed down. And none of this includes the long-term effects of poorly made, unmaintainable code that was farted out in bulk by an overworked engineer who didn’t have time to properly review code that they didn’t write and don’t fully understand.
It also doesn’t include the effects of long term exposure to LLMs reducing their solo effectiveness. If you only measure the immediate delta, then it could look like the LLM is helping when actually it’s just making people dependent.
And the selected dev quotes are also alarming in light of that information:
“I’m torn. I’d like to help provide updated data on this question but also I really like using AI!” — a developer from the original study early-2025 when asked to participate in the late-2025 study.
“I found I am actually heavily biased sampling the issues … I avoid issues like AI can finish things in just 2 hours, but I have to spend 20 hours. I will feel so painful if the task is decided as AI-disallowed.” — a developer from the new study noting selection effects when choosing what tasks to include in the study.
“my head’s going to explode if I try to do too much the old fashioned way because it’s like trying to get across the city walking when all of a sudden I was more used to taking an Uber.” — a developer from the new study noting selection effects when choosing what tasks to include in the study.
These quotes don’t demonstrate that LLMs actually help, only that they are addictive, which we already know to be true. If you’ve ever tried to talk to an addict about their problem you’d recognise this language.
Especially the quote that they could do something in 2 hours with an LLM that would take 20 hours alone. That can’t be true, that person is definitely wrong about the effect of the LLM. If it were really that effective, LLM companies would be clamouring to show the data that proves how effective their products are. Why aren’t they?
The fact this data is so hard to find and so hard to fund when there are so many billions being dumped into this field should tell you something, it should be deeply disturbing, but you just carry on fully convinced that you’re right and that there’s nothing to what I’m saying, even though you admitted you would’ve agreed just 3 months ago. Again, if you can actually show that the difference is so dramatic, then show it. You’re not though. You’re just convinced that you don’t need to re-evaluate what you believe. That doesn’t say good things about where your head’s at.
If you truly weren’t trying to convince me, you could just stop. I don’t know what you’re trying to prove by continuing.
This is just a statement of faith in your ability to judge these things accurately. Nowhere in here do I see any evidence that you’ve even considered that the reason you’ve changed your attitude towards the tech is that it’s just gotten so good at fooling people that it’s finally got you.
You don’t gain much from trying to convince me, but you could gain a lot from being more sceptical. People invented science to address the fact that our intuitive understanding doesn’t always reflect reality.
Science and the collection of objective data stops us from doing this:

There are a bunch of things that our brains just don’t understand intuitively, so we need to check our intuition against measurement. There’s no shame in that, but when it’s pointed out, then you have a chance to check yourself.
But you don’t seem to understand that. When you say:
Anyway, you’ll see all this eventually, when some data gets published.
you are demonstrating that you are the perfect mark for this stuff, because you are not reflecting on your own thought process to see where it might be failing you.
You’ve been given evidence that people cannot trust their own perceptions of what these agents do, and you replied by telling a bunch of stories about why you think you personally can trust your perceptions. My 12-year-old did the same thing when I tried to explain this to them.
Engineers being spread thinner to manage a wider number of tasks whilst reviewing shitty LLM noise that they didn’t write is inevitably going to make horrible code that’s impossible to maintain and will cost massive amounts of time and resources in the long run.
And the idea that it allows more things to be done is just a bunch of “it makes you faster” assessments in a trenchcoat.
Agentic or not, they still have zero fidelity. Fidelity can only come from an internal model of reality that the network is comparing its inputs to, and I’m pretty sure you don’t get that without AGI.
The data we have till this point shows that they don’t help, they only create an illusion of helping. And until you can show that that has fundamentally changed, then you have to assume that the improvements you’re seeing are just improved illusions.
Data or you’re just getting fooled better.
whilst it is adding some productivity
Is it though? Like what’s the evidence of that? If it just feels like it must be true, I have some bad news about that:
The most interesting part of this isn’t that it slowed them down when they expected to be faster, it’s that even after it slowed them down, they couldn’t tell and were fooled that they had been faster.
Look at the graph, especially the last two lines:
https://cdn.arstechnica.net/wp-content/uploads/2025/07/aicodingchart-1024x507.png
My theory about this is that LLMs were tasked with giving useful output, but they couldn’t do that, because they have no fidelity, so instead they found a shortcut, which was to trick people into thinking they were being useful. They found the same loophole that conmen have used for millenia, and automated it. It’s the AI alignment problem, only for some reason people aren’t talking about it, maybe because they don’t want to believe that we’re this easily manipulated.
There’s no reason to believe LLMs have gotten any better at actually doing useful work in the meantime in the absence of any objective measure of it. I think the best explanation for their “improvement” is that they have simply gotten better at fooling us.
Somewhere along the way our neoliberal overlords figured out that they needed to teach people to hate annoyance more than evil, and it’s been crazy effective.
That hole already serves the function of pushing out squishy things though.
{kind=link}
This is just a bunch of questions, but no answers, except for that whole paragraph about compute capacity whose point I simply cannot penetrate.
Just admit you don’t know that it makes people faster, you’re just dancing around that issue not saying anything.
EDIT:
Also:
Motherfucker, you told me what you were thinking and I took that at face value. You want to pretend that there’s some super-secret personal trove of knowledge that I can’t access that tells you the truth about what future data will say? Cool, I call that blind faith. I don’t know how you can pretend it’s anything else.